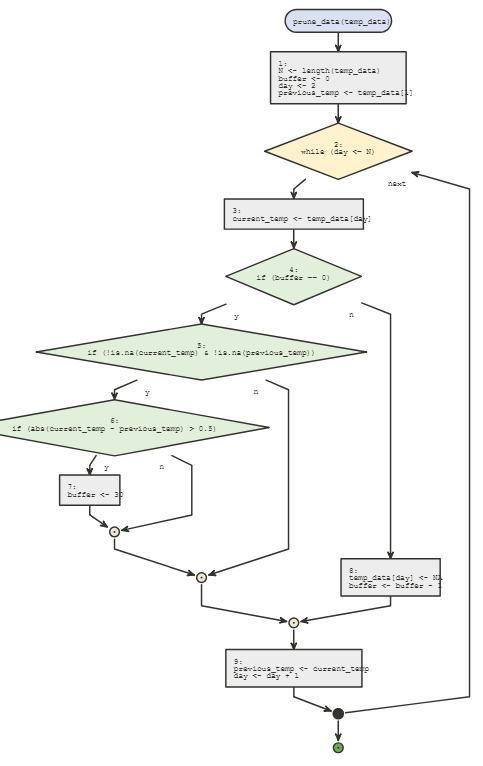
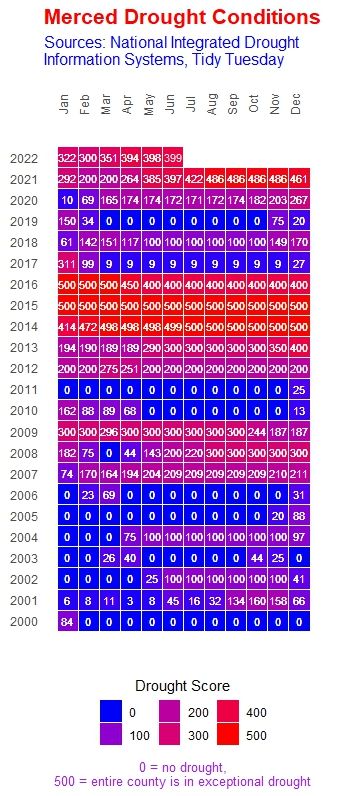
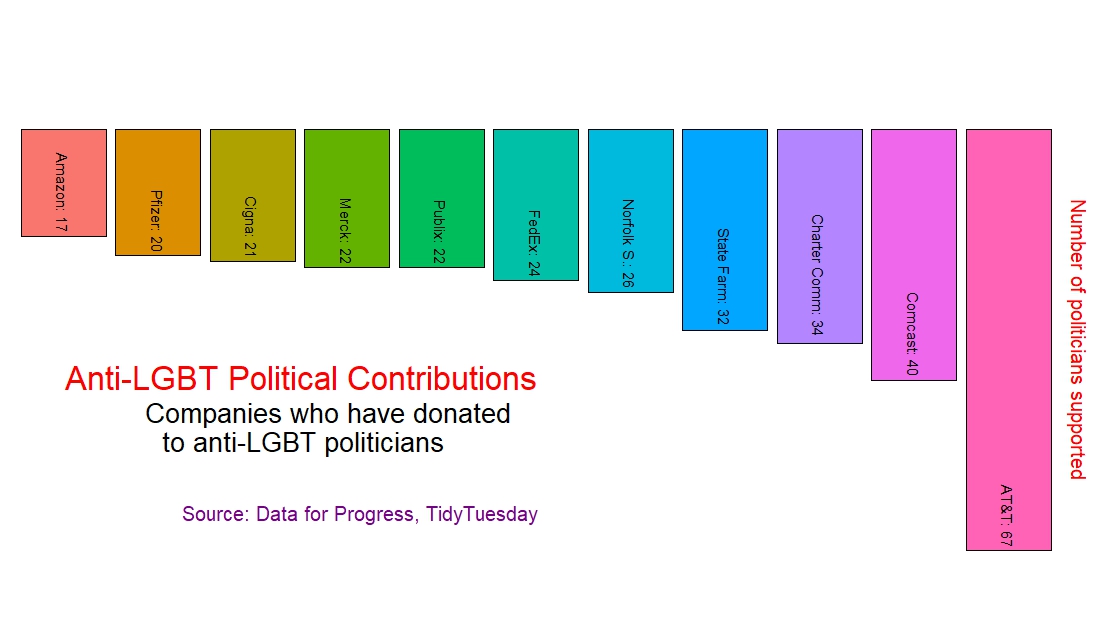
Kruskal-Wallis Test
I want to mentally prepare for the upcoming semester. Today, let me do a warm-up exercise of computing a Kruskal-Wallis test. library("palmerpenguins") library("tidyverse") You can see that I will use the ubiquitous Palmer Penguins data set str(penguins) ## tibble [344 × 8] (S3: tbl_df/tbl/data.frame) ## $ species : Factor w/ 3 levels "Adelie","Chinstrap",..: 1 1 1 1 1 1 1 1 1 1 ... ## $ island : Factor w/ 3 levels "Biscoe","Dream",.